[読了時間: 8分]
サンフランシスコ(5月19日~20日) 2年前は、ビッグデータなんて言っているコンサルタントは怪しいから気を付けろ、というのがむしろ肯定的に受け止められていた。今はそんな事を言う人はいないだろう。
ビッグデータ技術は、個人の遺伝子配列情報の解析から、新製品の売れ行き予想まで、将又貴方が次に見るべき映画のリコメンデーションから、今貴方がモバイルデバイスでブラウジングしているウェブページの広告枠に、どのブランドのどのクリエイティブのコンテンツを表示すれば一番高い確立でクリックしてもらえるかという判断にまで、ありとあらゆる分野で使われている。
製造業、サービス業、小売り販売、銀行、不動産、ゲーム出版、リクルート、TV、広告代理店など、つまりある程度の規模がある全ての業種だ。そしてこの技術を事業に活用しないと、かなりの確立で将来行き詰まってしまう恐れさえある。ちょっと前までは、商品データ、顧客データ、生産管理データ、販売管理データ、人事データなど、そういった事業に必要なデータはリレーショナルデータベース(RDBMS)にて管理しておけば、月報も年次決算も、場合によってはリアルタイムな数字も計算可能で、これで事足りていたはずだ。その上で、季節や天候による売り上げの増減は経験値で判断できたし、例えばTVや新聞広告を打った際の売り上げに対するインパクトといった事は、広告代理店からの数値をベースにした洞察に頼る事もできた。
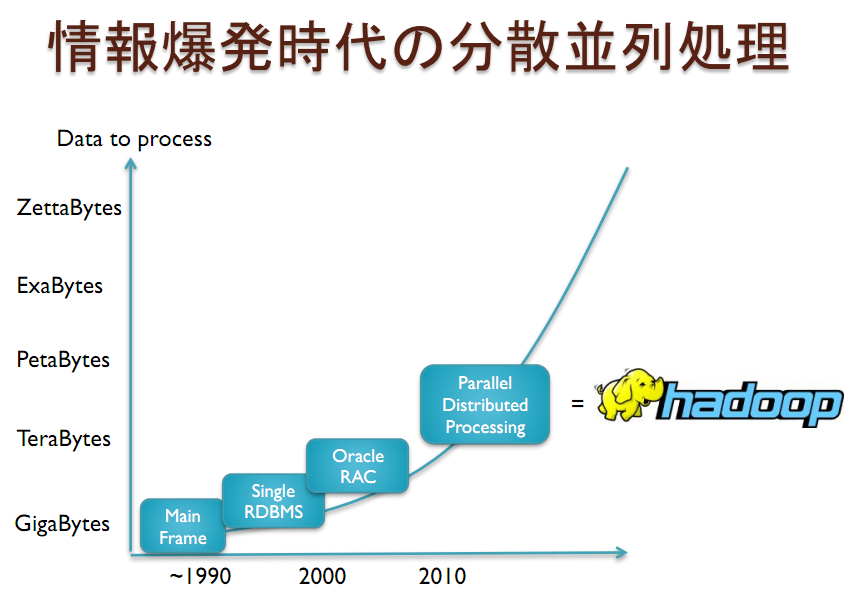
しかし今や状況がかなり変わってきた。我々は2012年の時点で、毎分当たり、27万回のTweetsをシェアし、72時間分の新規動画をYoutubeにアップロードし、アメリカのWalmartは1万7千回のトランスアクションをしと、甚大な量のデータを生み出し、Facebook CEOザックの法則によると、その量は毎年自乗倍数的に増え続けるという事だ。例えば最新のデータでは一日当たりのTweetsの数は5億回に達している。そういった人と人の連絡で生み出されるデータの他に、医療やヘスルケアのような機械と人、そしてGPSデバイスやバーコードスキャナーの用に機械間でやり取りされるデータもあるので、それらを全部合わせるとなるほど膨大な量になると理解できる。同時にそういったリアルタイムで延々発生し続けるデータを表計算ソフトやリレーショナルデータベースに整理する事は不可能な事に気づくはずだ。
ビッグデータを生かすという事は、そういった未整理なデータをどうやって事業の判断材料に生かせる形にするかという事で、関連する技術として、プラットフォームやアクセス手法にに始まり、コンセプトや用途の事なった各種製品とサービスが提供されてきている。前置きが長くなったが、第2回目となるDataBeat 2014では、ビッグデータ業界の大物が一同に集まり、業界のランドスケープを理解するには絶好の機会となった。
基調講演

キーノートを勤めたTom Davenportはアナリティックスやビジネス情報のマネージメントの大家であり、ベストセラー作家でもある。彼の話を要約してみる。2000年代前半まで続いた甚大で高価格でしかもあまり約に立たなかった1.0版データ管理システムに対して、2000年代後半に始まったアナリティックス2.0時代では、複雑で、膨大かつ未整理なビッグデータを利用する為に、新しいデータアクセスデザインや分析ツールが登場し、またデータサイエンティストなる職業が生み出された。2.0版のデータ管理と利用を真っ先に取り入れたのはオンライン企業であり、例えばGoogle、Linkedin、Netflix、Zillow、Facebookなど、どの商品にどう使われているのかはご想像にお任せする。
アナリティックス3,0時代では、事業の基幹データベースとビックデータをシームレスに合わせて扱えるようになり、且つそれらをリアルタイムで色々な角度から自由に視覚化し、各業界向けにカスタマイズされた分析ツールとして提供される。そして、アナリティックスは全ての関係者の必須業務となる。それが現在我々が措かれている状況だという。
TamrのCEO、Andy Palmerは来るべきデータ時代に先駆けて社内のリレーショナルデータベースとビッグデータをクリーンに統合する機能に絞ったアプリを発表した。企業内には既にして沢山のデータベースが存在している。エクセルからOracleまでと言えば分かりやすいだろうか。さらに企業を買収したりすると、方式の異なるデータベースがもっと増えてしまう。Tamrはこれらの項目や形式、そしてスキマをディープラーニングにより、最小限の労力で統合していく。それでもAIでは分からない所はエキスパート(もしくはデータの作成者)に直接問い合わせるメッセンジャー機能も含まれている。
PinterestのエンジニアのJie LiはHadoopやHiveといった多くの企業が採用しているシステム構成では無く、昨年の3月からAmazone AWSで提供が始まったRedShift、クラウドベースデータウェアハウスを使っていて、今まで以上の効率が上がった。
IBMのWatsonスーパーコンピューターグループのCTOであるRob Highは2001年にIBMがHuman Genome Projectを主導した事もあり(当時は遺伝子配列の解析に1年の月日と1億ドルの費用がかかった)、ヘルスケア分野でのビッグデータの活用を推し進める事で人類に貢献したい。
Linkedinの上級ビジネスアナリストのSimon ZhangはLinkedinネットワークの人と人の関連性と重みを把握しているので、どの人物がその会社でLinkedinにお金を使ってくれるか、誰が決済を下すのか、どのくらい使ってくれるのかも予測可能だと、つまりLinkedinの商品を顧客にもっと沢山販売するのに役立てているとの事。
Alpine Data Labs<http://alpinenow.com>のCMO、Bruno Azizaはビッグデータアナリティックスをもっと身近なツールにしたい。そこでアナリティックスツールにチャット機能をビルトインした結果、社内のエキスパートにアドバイスを聞いたり、同僚とシェアしたりするコラボの形が出来て身近になった。

Alpine Data Labs, CMO, Bruno Aziza氏
上場したばかりのZendeskのCTO、Joshua Bloomは、Wise.ioのマシンラーニング技術を使って効率を上げている。ヘルプデスクでは何度も同じ質問がある際には、AIにより対応できるので、そうする事でリアルなサポート担当は、本当に必要な仕事に集中できるとの事。
大手広告代理、Public GroupeのデジタルスタートアップVivaKiのEVP、Dan Buczaczerは仮想インテリジェンスとデータビジュアライゼーションのツールであるQuidを駆使して、ビッグデータの中に隠れている言葉や色などの消費者動向から、事件やニュースによるインパクトといった大局的判断までと、ビッグデータアナリティックスを広告制作における創造的ツールとして使っている。
もちろん、ビッグデータのOSとも言えるHadoop分散処理ソフトウェアプフレームワークの2台ベンダーのClouderaとHortonworks、そしてオープンソースのNoSQLでシェアが高いMangoDBの登壇もあった。
紹介できなかった会社をリストアップしておくので、興味のある方はGoogleしてみよう。
AdRoll、Tableau、Declara、ClearStory Data、SiSense、MarketShare、MetaMarkets、Trifacta、Infer、Splunk、6Sense、Datahero、New Relic、Rubicon Project、TIBCO、Segment.io、Ayasdi、Databricks、Datameer、Mode Analytics、Altiscale、Looker、Rocket Fuel and so on.
【関連URL】
・DataBeat 2014 イベントページ
http://events.venturebeat.com/event/databeat2014/
・主催元VentureBeatのDataBeat 2014カバレッジ
http://venturebeat.com/tag/databeat-2014/
・DataBeat 2014 写真
https://twitter.com/MICKEYTACHIBANA/media
蛇足:Mickey’s インスピレーション、
ビッグデータとHadoopという言葉を初めて聞いたのはそんなに昔の事では無い。トランズアクション、ウェブトラッフィック、ソーシャルメディア、マシンジェネレーテッドメディア、生体データなどあらゆるデータを生データで保存蓄積し始めたのはそんなに昔では無いので、この技術はまだ始まったばかりだ。
よって、全ての企業をざくっと押し並べてみて、それらのせいぜい12~13%ぐらいしか役立てていないとも書かれていたのを記憶している。ビッグデータをマーケティングや経営に利用する事によって、データドリブンな事業判断はこれから先、2倍、3倍も精度が上がる可能性を秘めている。そういった背景の元にビッグデータ関連スタートアップ企業が乱立し、また非常に早い期間でIPOやバイアウトされている事実もある。またビッグデータを利用する側の企業も、いかに競合より早くシステムを構築し、運用を開始できるかが死活問題になってくるだろう。Tamr、Bottomnoseに関しては、個別取材をしたので、別途記事を書きたいと考えている。
Tags:
- Airbnb,
- AMAZON,
- AmazonRedshift,
- Analytics,
- Big Data,
- Data,
- Facebook,
- hadoop,
- IBM,
- LINKEDIN,
- NoSQL,