1990年代初頭から記者としてまた起業家としてITスタートアップ業界のハードウェアからソフトウェアの事業創出に関わる。シリコンバレーやEU等でのスタートアップを経験。日本ではネットエイジ等に所属、大手企業の新規事業創出に協力。ブログやSNS、LINEなどの誕生から普及成長までを最前線で見てきた生き字引として注目される。通信キャリアのニュースポータルの創業デスクとして数億PV事業に。世界最大IT系メディア(スペイン)の元日本編集長、World Innovation Lab(WiL)などを経て、現在、スタートアップ支援側の取り組みに注力中。
Latest posts by maskin (see all)
- 「ソラコム」がスイングバイIPOを実現、東証グロース市場上場承認 - 2024-02-22
- (更新)結果速報 LAUNCHPAD SEED#IVS2023 #IVS #IVS @IVS_Official - 2023-03-09
- 「始動 Next Innovator 2022」締め切りは9月5日(月)正午ー経産省・JETRO主催のイノベーター育成プログラム #始動2022 - 2022-09-01
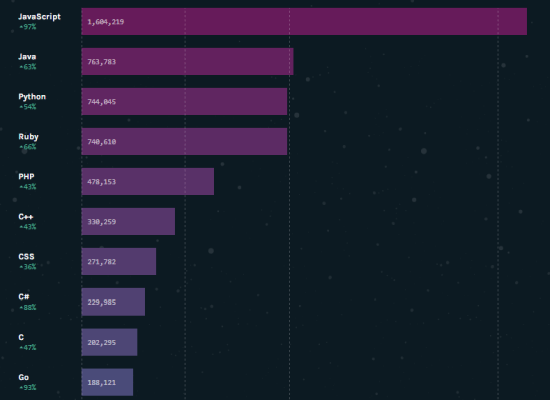
北米を中心に全世界でJavaScriptへの対応熱止まらない。
今回も知る人ぞ知るオープンソースの文字認識エンジン「Tesseract-OCR」が、JavaScriptに移植され話題になっている。
以下は「tesseract.jp」のデモ画像。ウェブ上で画像の取得から一連の文字認識のプロセスが確認できる。

「Tesseract-OCR」は、もともと、米HP社が1984年から1994年にかけて研究した成果のプロトタイプがオープンソースとして提供されたもの([PDF])。
62種類以上の言語に対応しており、それぞれで認識データを機械学習させることで精度が向上するという。公式サイトでは、英語・中国語・ロシア語のデモが公開されているが、英語はほぼ100%。難易度の高い中国語ではエラーが目立ったが内容が読めないほどではなかった。
クラウドの文字認識サービス「Google Cloud Vision」(有料)あたりのほうが精度が高いと思われるが、「Tesseract」でも一定の文字サイズがあればかなり高い確立で認識するという声もある。また、Tesseractは文字認識データの学習効果により精度を高めることができるため、特定用途で実用的導入も期待できそうだ。
【関連URL】
・Tesseract.js | Pure Javascript OCR for 62 Languages!
http://tesseract.projectnaptha.com
・naptha/tesseract.js: Pure Javascript OCR for 62 Languages
https://github.com/naptha/tesseract.js
蛇足:僕はこう思ったッス
 OCRは精度こそ重要。デモを試する限り、アルファベットの認識はかなりのもの。JavaScriptに移植されたことで、各種サービスなどへの応用が期待できる。アイディアを考え出したらキリがない。ウェブサービスへの導入はもちろん、ハイブリッドアプリへの導入などなど、実用的な用途が多数考えられる。JavaScriptで使られた使いまわしの効くOCRエンジンへの期待は高い。
OCRは精度こそ重要。デモを試する限り、アルファベットの認識はかなりのもの。JavaScriptに移植されたことで、各種サービスなどへの応用が期待できる。アイディアを考え出したらキリがない。ウェブサービスへの導入はもちろん、ハイブリッドアプリへの導入などなど、実用的な用途が多数考えられる。JavaScriptで使られた使いまわしの効くOCRエンジンへの期待は高い。
OCRは精度こそ重要。デモを試する限り、アルファベットの認識はかなりのもの。JavaScriptに移植されたことで、各種サービスなどへの応用が期待できる。アイディアを考え出したらキリがない。ウェブサービスへの導入はもちろん、ハイブリッドアプリへの導入などなど、実用的な用途が多数考えられる。JavaScriptで使られた使いまわしの効くOCRエンジンへの期待は高い。